3/3/2026
通义千问团队一口气发布了四款小模型:Qwen3.5-0.8B、2B、4B、9B,采用 Gated DeltaNet 混合架构,9B 性能直逼 120B 大模型,马斯克直呼"令人惊艳的智能密度"。

3 月 2 日深夜,阿里通义千问团队在 X 平台正式宣布开源 Qwen3.5 小尺寸模型系列,覆盖 0.8B、2B、4B 和 9B 四个参数规格,专为笔记本电脑、手机等端侧设备设计,一经发布便在海内外开发者圈引发强烈反响。
仅发布三小时后,马斯克便出现在评论区,留下了他的评价:
"Impressive intelligence density"(令人惊艳的智能密度)
四个尺寸,一套架构
四款模型用的是同一套 Gated DeltaNet 混合架构,按 3:1 的比例混合了线性注意力和标准注意力模块:
- 75% 的层使用 Gated DeltaNet(线性注意力)
- 25% 的层保留 Gated Attention(标准注意力)
线性注意力的核心优势:内存消耗恒定,不会因为输入文本变长就爆显存。
传统 Transformer 的注意力计算量与序列长度的平方成正比,Gated DeltaNet 把这个关系拉成线性。处理一个 10 分钟的视频,传统方式可能需要 64G 显存,用 Gated DeltaNet 只需 16G 就够了。
此外,四款模型全部支持:
- 原生多模态(早期融合训练,文本 + 图像 + 视频统一处理)
- 26 万 Token 超长上下文窗口
- 思考 / 非思考双模式(深度推理与快速响应自由切换)
- Apache 2.0 开源协议,可商用,支持 LoRA / 全量微调
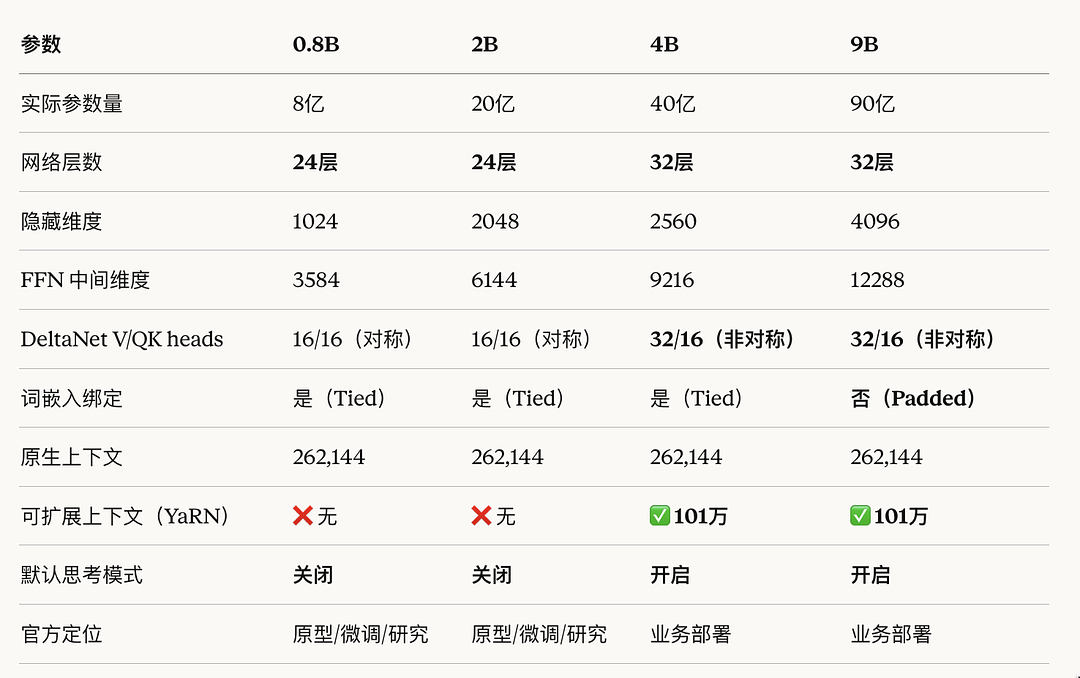
四款模型详解
Qwen3.5-0.8B:不到 10 亿参数,手机都能跑
- 层数:24 层,隐藏维度 1024
- 定位:极致轻量,端侧首选
- 场景:移动设备、IoT 边缘设备、低延时实时交互
- 亮点:尽管 MMLU-Pro 得分 29.7 较为平平,但受益于早期融合多模态架构,视觉任务 MathVista 达到 62.2,OCRBench 74.5,展现出与参数量不相称的视觉理解能力
Qwen3.5-2B:轻量级多面手,OCR 识别准确率达到 84.5
- 层数:24 层,隐藏维度 2048
- 定位:极致轻量,端侧首选
- 场景:移动终端、物联网边缘设备、实时交互
- 亮点:OCRBench 达到 84.5,文字识别能力亮眼;有开发者已在 iPhone 17 Pro 上通过 MLX 框架本地运行,实现实时视觉理解与问答
Qwen3.5-4B:多模态能力扎实,定位轻量级 AI Agent 开发
- 层数:32 层,隐藏维度 2560
- 定位:轻量级 Agent 的强劲基座
- 场景:轻量级智能体核心大脑,智能客服、个人助理等多轮对话场景
- 亮点:在多语言知识、视觉推理、文档理解等任务上媲美更大模型;官方将其定性为"出乎意料强大的多模态轻量智能体底座"
Qwen3.5-9B:这次的明星选手,性能直逼大模型
- 层数:32 层,隐藏维度 4096,FFN 维度 12288
- 定位:紧凑尺寸,越级性能
- 场景:需要较高智力水平但显存资源受限的服务器端部署
- 亮点:
- MMLU-Pro 得分 82.5,超越参数量为其三倍的上一代 Qwen3-30B
- MMMU-Pro 得分 70.1,在该项测试中以 13 分优势击败 GPT-5-Nano
- MathVision 达到 78.9,证明复杂物理和数学图像解析能力
- 性能媲美 GPT-OSS-120B,体积却只有其十三分之一
- 可在 Mac 上流畅运行,完全免费
性能评测:9B 打赢了谁?
在 GPQA Diamond、MMMU-Pro、ERQA、Video-MME 等多项评测中,Qwen3.5-9B 大幅领先:
| 模型 | MMMU-Pro | 参数量 | |------|----------|--------| | Qwen3.5-9B | 70.1 | 9B | | GPT-5-Nano | 57.1 | 未知 | | GPT-OSS-20B | - | 20B | | Gemini 2.5 Flash-Lite | - | - | | Qwen3-Next-80B-A3B | - | 80B |
一个可以在笔记本电脑上运行的模型,性能却超越了云端旗舰级的 Nano 模型,架构优势远胜于参数数量。—— 开发者评论
开发者圈的真实反应
Mac mini 搭建 AI 员工站:有开发者在 Mac mini 上部署 Qwen3.5-9B 配合 OpenClaw 系统,构建出成本低于初级员工月薪的 AI 工作站。
256k 上下文实测:另一位开发者使用 AMD Ryzen AI Max+395 处理器配合 Q4_K_XL 量化算法,在 256k 上下文窗口下实现每秒 30 个 token 的处理速度,且显存占用不足 16GB。
iPhone 本地运行:有网友演示了在 iPhone 17 Pro 上通过 MLX 框架本地运行 Qwen3.5-2B 6-bit 版本,模型可实时完成视觉理解与问答任务。
Ollama 支持:知名开源推理工具 Ollama 迅速跟进官宣支持 Qwen3.5 全系四个尺寸,只需一行命令即可拉取运行:
ollama run qwen3.5:9b
客观看待:小模型的边界
当然,也有开发者给出了更客观的评价:
4B 模型只是一个智能自动补全工具,而不是一个思考伙伴。GPQA Diamond(研究生水平推理)的正确率约为 45%,HMMT 数学测试的正确率约为 15%。这意味着它在难题上超过一半的概率都会出错。
小型模型的能力固然有限,但其在特定能力维度评测上已达到 Gemini 3 Flash 等云端部署模型的水平,意味着其已经能在很多端边侧场景发挥实际效用。
Qwen3.5 完整家族
至此,千问 3.5 家族已全部开源(共 8 款):
| 规格 | 模型 | |------|------| | 大尺寸 | Qwen3.5-397B-A17B | | 中型 | Qwen3.5-122B-A10B、Qwen3.5-35B-A3B、Qwen3.5-27B | | 小尺寸 | Qwen3.5-9B、Qwen3.5-4B、Qwen3.5-2B、Qwen3.5-0.8B |
所有模型均已在以下平台开源,开发者可立即下载体验:
- Hugging Face:https://huggingface.co/collections/Qwen/qwen35
- 魔搭社区(ModelScope):https://modelscope.cn/collections/Qwen/Qwen35
- Ollama:https://ollama.com/library/qwen3.5
写在最后
Qwen3.5 小模型系列的发布,填补了从 0.8B 到 397B 完整产品矩阵的最后一块拼图。马斯克的"智能密度"评价并非溢美之词——用 9B 的体积实现 120B 的性能,这正是架构创新超越参数堆砌的最好注脚。
对于开发者而言,真正有价值的,是与正确硬件深度绑定、以正确量化格式部署的小模型。端侧 AI 的时代,已经到来。