3/3/2026
Alibaba's Qwen team releases four small models — Qwen3.5-0.8B, 2B, 4B, and 9B — built on a Gated DeltaNet hybrid architecture. The 9B model rivals 120B-scale performance, earning Elon Musk's praise for "impressive intelligence density."

On the night of March 2, Alibaba's Qwen team officially announced the open-source release of the Qwen3.5 small model series on X — covering four parameter scales: 0.8B, 2B, 4B, and 9B. Designed for edge devices like laptops and smartphones, the announcement immediately sparked intense discussion among developers worldwide.
Just three hours after launch, Elon Musk appeared in the comments with a single line:
"Impressive intelligence density."
Four Sizes, One Architecture
All four models share the same Gated DeltaNet hybrid architecture, mixing linear and standard attention modules at a 3:1 ratio:
- 75% of layers use Gated DeltaNet (linear attention)
- 25% of layers retain Gated Attention (standard attention)
The core advantage of linear attention: constant memory consumption regardless of input length.
Traditional Transformer attention scales quadratically with sequence length. Gated DeltaNet brings this down to linear. Processing a 10-minute video? A standard approach might need 64GB VRAM — with Gated DeltaNet, 16GB is enough.
All four models also support:
- Native multimodality (early-fusion training — text, images, and video unified from the ground up)
- 260K token context window
- Thinking / non-thinking dual mode (switch between deep reasoning and fast response)
- Apache 2.0 license — commercially usable, supports LoRA and full fine-tuning
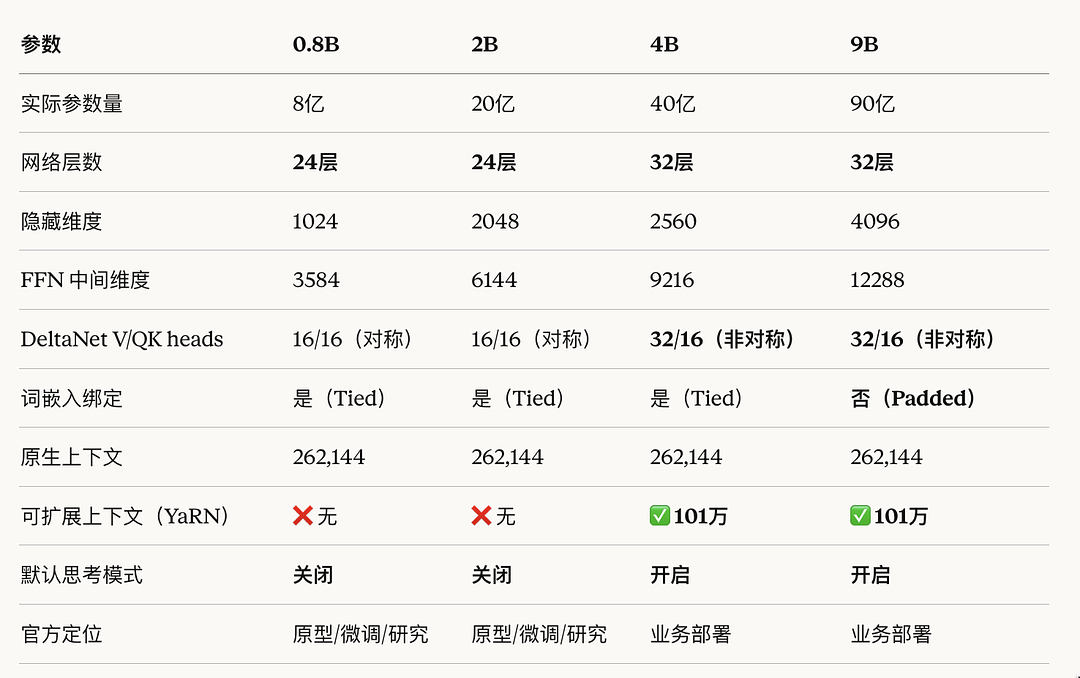
Model Breakdown
Qwen3.5-0.8B: Under 1B Parameters — Runs on a Phone
- Architecture: 24 layers, hidden dim 1024
- Target: Ultra-lightweight, edge-first
- Use cases: Mobile devices, IoT edge, low-latency real-time interaction
- Highlights: MMLU-Pro scores 29.7 (modest), but thanks to early-fusion multimodal training, MathVista hits 62.2 and OCRBench reaches 74.5 — visual capability well beyond its parameter count
Qwen3.5-2B: Lightweight All-Rounder, OCR at 84.5
- Architecture: 24 layers, hidden dim 2048
- Target: Ultra-lightweight, edge-first
- Use cases: Mobile terminals, IoT devices, real-time interaction
- Highlights: OCRBench at 84.5 is impressive. Developers have already run it locally on an iPhone 17 Pro via the MLX framework, achieving real-time visual understanding and Q&A
Qwen3.5-4B: Solid Multimodal — Built for Lightweight AI Agents
- Architecture: 32 layers, hidden dim 2560
- Target: Powerful base for lightweight agents
- Use cases: Core brain for lightweight AI agents, customer service bots, personal assistants
- Highlights: Matches larger models on multilingual knowledge, visual reasoning, and document understanding. Officially described as a "surprisingly capable lightweight multimodal agent base"
Qwen3.5-9B: The Star of the Lineup — Punches Way Above Its Weight
- Architecture: 32 layers, hidden dim 4096, FFN dim 12288
- Target: Compact size, class-defying performance
- Use cases: Server-side deployment where high intelligence is needed but VRAM is limited
- Highlights:
- MMLU-Pro: 82.5 — surpasses Qwen3-30B (3× the parameters)
- MMMU-Pro: 70.1 — beats GPT-5-Nano by 13 points
- MathVision: 78.9 — strong complex visual math reasoning
- Rivals GPT-OSS-120B at just 1/13 the size
- Runs smoothly on a Mac, completely free
Benchmark Results: Who Did 9B Beat?
Qwen3.5-9B leads across GPQA Diamond, MMMU-Pro, ERQA, and Video-MME:
| Model | MMMU-Pro | Parameters | |-------|----------|------------| | Qwen3.5-9B | 70.1 | 9B | | GPT-5-Nano | 57.1 | Unknown | | GPT-OSS-20B | — | 20B | | Gemini 2.5 Flash-Lite | — | — | | Qwen3-Next-80B-A3B | — | 80B |
A model that runs on a laptop, yet outperforms cloud-hosted flagship Nano models. Architecture beats raw parameter count. — Developer comment
What Developers Are Actually Doing With It
AI workstation on a Mac mini: One developer deployed Qwen3.5-9B with OpenClaw on a Mac mini, building an AI work system that costs less per month than a junior employee's salary.
256k context in the wild: Another developer used an AMD Ryzen AI Max+395 with Q4_K_XL quantization — achieving ~30 tokens/sec at full 256k context, with under 16GB VRAM.
Running on iPhone: A developer demonstrated Qwen3.5-2B (6-bit) running locally on an iPhone 17 Pro via the MLX framework, handling real-time visual understanding and question answering.
Ollama support: Ollama quickly announced full support for all four sizes. One command to pull and run:
ollama run qwen3.5:9b
An Honest Look: Where Small Models Fall Short
Not all reactions were pure enthusiasm:
The 4B model is an intelligent autocomplete tool, not a thinking partner. GPQA Diamond accuracy is around 45%, and HMMT math accuracy is about 15%. That means it gets hard questions wrong more than half the time.
Small models have real limits. But at specific capability dimensions, they've reached the level of cloud-deployed models like Gemini 3 Flash — which means they're ready to deliver genuine value in many edge and on-device scenarios.
The Complete Qwen3.5 Family
With these four models, the entire Qwen3.5 family is now open-source (8 models total):
| Size | Models | |------|--------| | Large | Qwen3.5-397B-A17B | | Medium | Qwen3.5-122B-A10B, Qwen3.5-35B-A3B, Qwen3.5-27B | | Small | Qwen3.5-9B, Qwen3.5-4B, Qwen3.5-2B, Qwen3.5-0.8B |
All models are available now:
- Hugging Face: https://huggingface.co/collections/Qwen/qwen35
- ModelScope: https://modelscope.cn/collections/Qwen/Qwen35
- Ollama: https://ollama.com/library/qwen3.5
Final Thoughts
The Qwen3.5 small model release fills the last gap in a complete product matrix from 0.8B to 397B. Musk's "intelligence density" comment isn't hyperbole — achieving 120B-scale performance in a 9B body is exactly what architectural innovation over raw parameter stacking looks like.
For developers, what truly matters isn't the benchmark number. It's a small model deployed on the right hardware, in the right quantization format — that becomes a real product. The era of on-device AI is here.